import os # Configure which GPU if os.getenv("CUDA_VISIBLE_DEVICES") isNone: gpu_num = 0# Use "" to use the CPU os.environ["CUDA_VISIBLE_DEVICES"] = f"{gpu_num}"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# Import Sionna import sionna.phy
# Configure the notebook to use only a single GPU and allocate only as much memory as needed # For more details, see https://www.tensorflow.org/guide/gpu import tensorflow as tf gpus = tf.config.list_physical_devices('GPU') if gpus: try: tf.config.experimental.set_memory_growth(gpus[0], True) except RuntimeError as e: print(e) # Avoid warnings from TensorFlow tf.get_logger().setLevel('ERROR')
import numpy as np %matplotlib inline import matplotlib.pyplot as plt import time
Sionna 提供了一个工具函数,用于根据比特能量与噪声功率谱密度比 $Eb/N0$ (以 dB 为单位)以及各种参数(如编码率和每符号比特数)来计算噪声功率谱密度比 $N0$ 。
1 2 3
no = sionna.phy.utils.ebnodb2no(ebno_db=10.0, num_bits_per_symbol=NUM_BITS_PER_SYMBOL, coderate=1.0) # Coderate set to 1 as we do uncoded transmission here
classUncodedSystemAWGN(sionna.phy.Block): def__init__(self, num_bits_per_symbol, block_length): """ A Sionna Block for uncoded transmission over the AWGN channel Parameters ---------- num_bits_per_symbol: int The number of bits per constellation symbol, e.g., 4 for QAM16. block_length: int The number of bits per transmitted message block (will be the codeword length later). Input ----- batch_size: int The batch_size of the Monte-Carlo simulation. ebno_db: float The `Eb/No` value (=rate-adjusted SNR) in dB. Output ------ (bits, llr): Tuple: bits: tf.float32 A tensor of shape `[batch_size, block_length] of 0s and 1s containing the transmitted information bits. llr: tf.float32 A tensor of shape `[batch_size, block_length] containing the received log-likelihood-ratio (LLR) values. """
super().__init__() # Must call the block initializer
EBN0_DB_MIN = -3.0# Minimum value of Eb/N0 [dB] for simulations EBN0_DB_MAX = 5.0# Maximum value of Eb/N0 [dB] for simulations BATCH_SIZE = 2000# How many examples are processed by Sionna in parallel
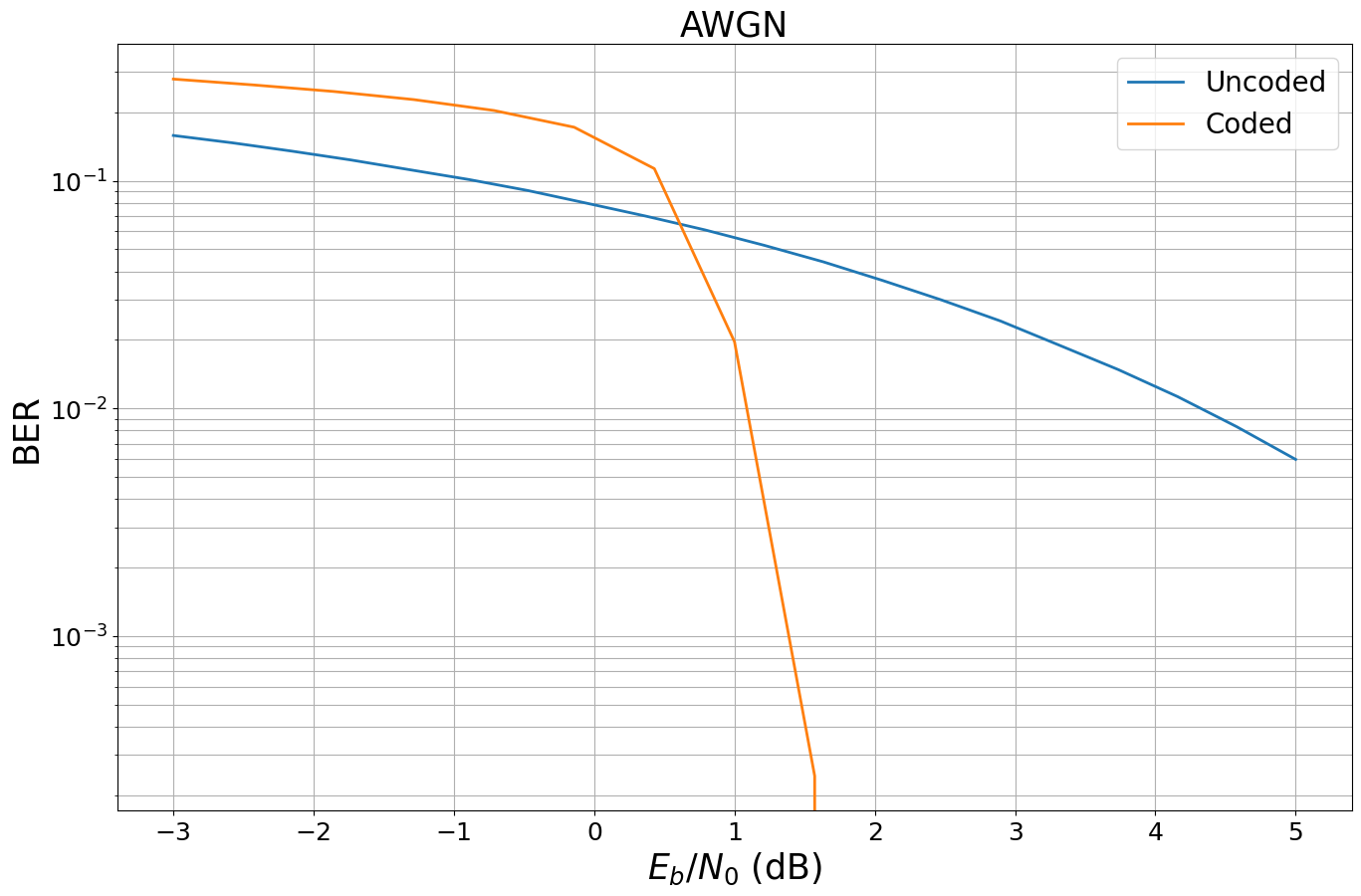
ber_plots = sionna.phy.utils.PlotBER("AWGN") ber_plots.simulate(model_uncoded_awgn, ebno_dbs=np.linspace(EBN0_DB_MIN, EBN0_DB_MAX, 20), batch_size=BATCH_SIZE, num_target_block_errors=100, # simulate until 100 block errors occured legend="Uncoded", soft_estimates=True, max_mc_iter=100, # run 100 Monte-Carlo simulations (each with batch_size samples) show_fig=True);
然而,Sionna 的功能更多——它支持 N 维输入张量,从而允许在单个命令行中处理多个用户和多个天线的多个样本。假设我们想要为每个连接到每个的 `num_users` 个用户编码长度为 `n` 的 `batch_size` 个码字。这意味着总共传输 `batch_size` * `n` * `num_users` * `num_basestations` 个比特。 ```python BATCH_SIZE = 10 # samples per scenario num_basestations = 4 num_users = 5 # users per basestation n = 1000 # codeword length per transmitted codeword coderate = 0.5 # coderate
k = int(coderate * n) # number of info bits per codeword
# instantiate a new encoder for codewords of length n encoder = sionna.phy.fec.ldpc.LDPC5GEncoder(k, n)
# the decoder must be linked to the encoder (to know the exact code parameters used for encoding) decoder = sionna.phy.fec.ldpc.LDPC5GDecoder(encoder, hard_out=True, # binary output or provide soft-estimates return_infobits=True, # or also return (decoded) parity bits num_iter=20, # number of decoding iterations cn_update="boxplus-phi") # also try "minsum" decoding
# draw random bits to encode u = binary_source([BATCH_SIZE, num_basestations, num_users, k]) print("Shape of u: ", u.shape)
# We can immediately encode u for all users, basetation and samples # This all happens with a single line of code c = encoder(u) print("Shape of c: ", c.shape)
print("Total number of processed bits: ", np.prod(c.shape))
这种方式适用于任意维度,并允许将设计的系统简单地扩展到多用户或多天线场景。
用极码替换 LDPC 码。API 保持相似。
1 2 3 4 5 6
k = 64 n = 128
encoder = sionna.phy.fec.polar.Polar5GEncoder(k, n) decoder = sionna.phy.fec.polar.Polar5GDecoder(encoder, dec_type="SCL") # you can also use "SCL"
classCodedSystemAWGN(sionna.phy.Block): def__init__(self, num_bits_per_symbol, n, coderate): super().__init__() # Must call the Sionna block initializer
#@tf.function # activate graph execution to speed things up defcall(self, batch_size, ebno_db): no = sionna.phy.utils.ebnodb2no(ebno_db, num_bits_per_symbol=self.num_bits_per_symbol, coderate=self.coderate)
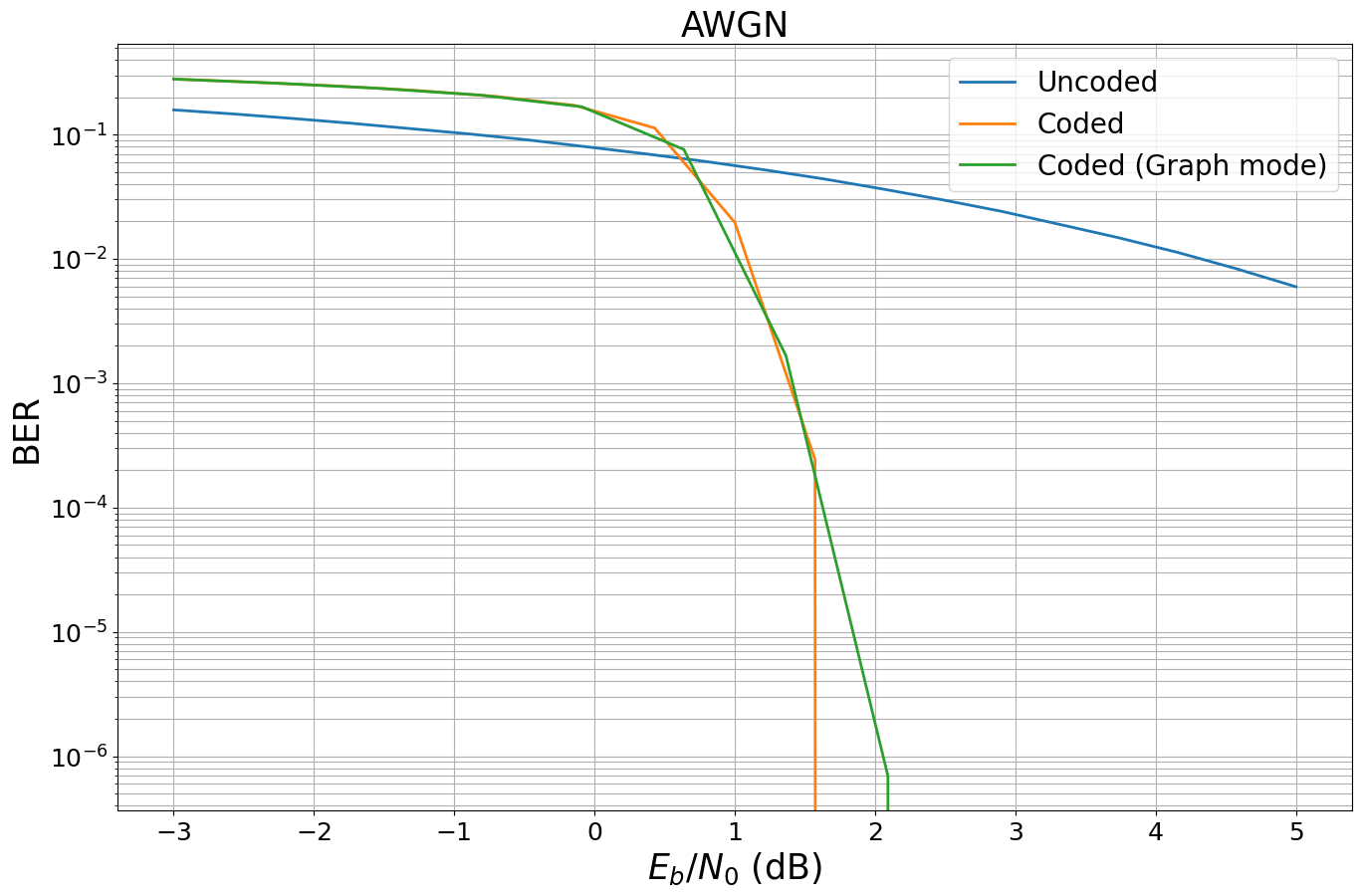
@tf.function() # enables graph-mode of the following function defrun_graph(batch_size, ebno_db): # all code inside this function will be executed in graph mode, also calls of other functions print(f"Tracing run_graph for values batch_size={batch_size} and ebno_db={ebno_db}.") # print whenever this function is traced return model_coded_awgn(batch_size, ebno_db)
batch_size = 10# try also different batch sizes ebno_db = 1.5
# run twice - how does the output change? run_graph(batch_size, ebno_db)